Atlan Submission - Shivam Mehta
❓ Design a sample schematic for how you would store forms (with questions) and responses (with answers) in the Collect data store. Forms, Questions, Responses, and Answers each will have relevant metadata. Design and implement a solution for the Google Sheets use case and choose any one of the others to keep in mind how we want to solve this problem in a plug-n-play fashion. Make fair assumptions wherever necessary.
❓ Eventual consistency is what the clients expect as an outcome of this feature, making sure no responses get missed in the journey. Do keep in mind that this solution must be failsafe, should eventually recover from circumstances like power/internet/service outages, and should scale to cases like millions of responses across hundreds of forms for an organization.
❓ There are points for details on how would you benchmark, set up logs, monitor for system health, and alerts for when the system health is affected for both the cloud as well as bare-metal.
Read up on if there are limitations on the third party ( Google sheets in this case ) too, a good solution keeps in mind that too.
Submission
Assumptions : The current backend system for Collect is monolithic.
The main take away for me from the problem statement is that the system can be eventually consistent, scaled to millions of responses, and the solution must be independent of the backend monolith. The last requirement entails a flexible architecture wherein, the features can be added without disturbing the monolith backend and hence, the problem statement demands a plug-and-play architecture. As stated in the use cases, many of these requirements create an overhead on the backend un-necessarily and hence, needs to be decoupled as much as possible. In my opinion, to create decoupled applications which can be scaled independently and for implementation of a plug-and-play architecture, plugins/actions as microservices would suffice requirements stated by the problem statement. Using microservice seems apt for the following reasons:
- Decoupling of the main backend api service and plugins (microservices)
- Individual scaling of plugins. (Google sheet plugin might be used for 1 million users but the slang plugin would be only used for 1000 users, hence, each of these plugins with their unique requirements needs to be scaled differently.)
- Security. (Due to added layer api gateway and RBAC/ACLs in the access layer)
For the Google Sheet use case, the product/feature requirements can be of two types:
1) The user manually ports the data into the google sheet using UI.
Figure 2. represents the architecture for the manual porting of the users using the UI click. First of all, we take users google Oauth permissions to create,edit and delete google sheets. This would look something like this (Figure 1):

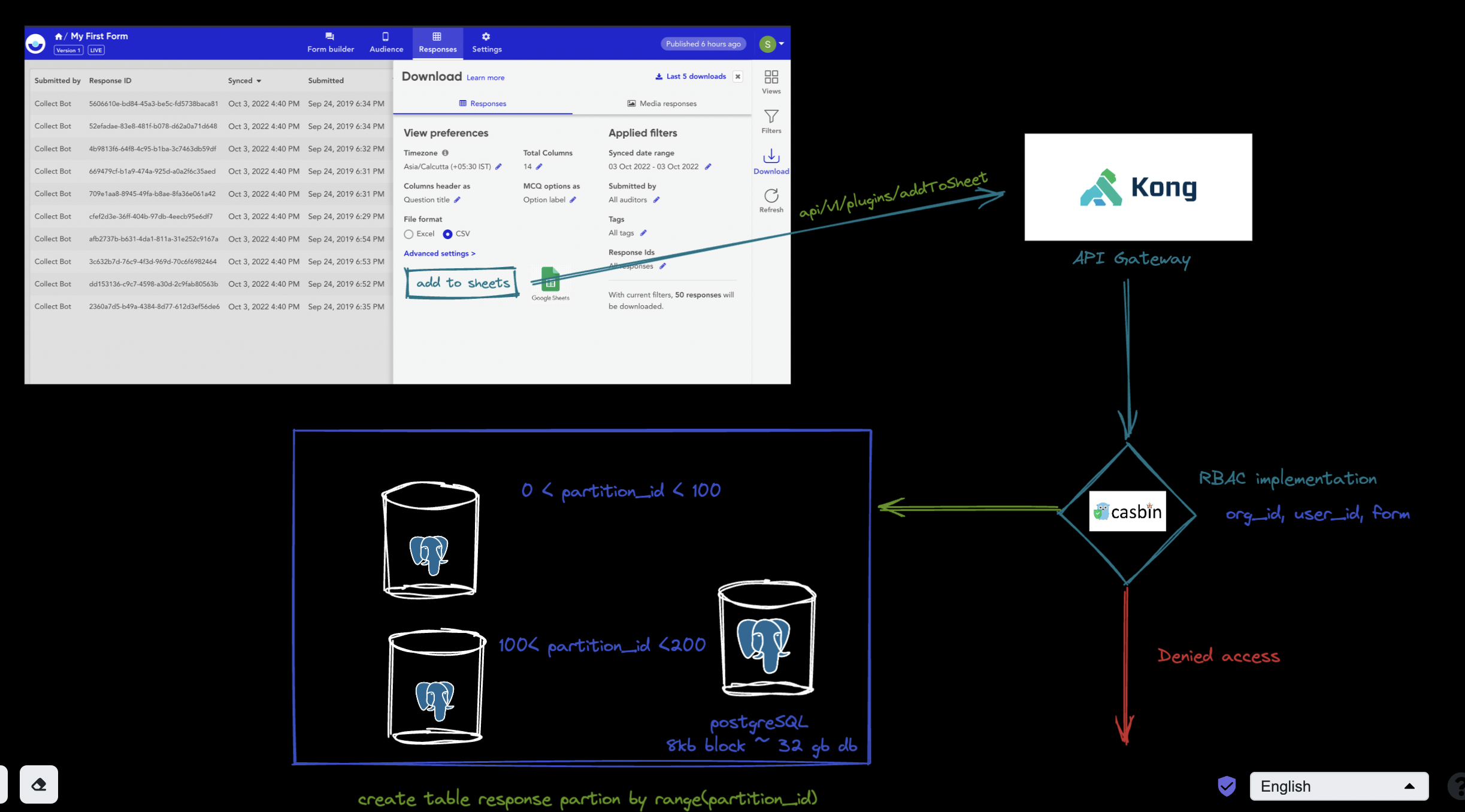

After getting the permissions, we can add a button at download modal which would communicate to our api gateway kong. The choice of kong was made due to it’s flexibility and customisability which would be really helpful in integrating new plugins/integration later. For example, to add feature of google sheet plugin, we can define an API endpoint /plugin/sheet and kong will easily redirect it to our plugin microservice. With kong, we can also integrate casbin for our RBAC (Role based access control) feature.

The current route https://collect.atlan.com/api/v1/functions/getOrgLevelPermissions , can be moved to proxy layer using casbin instead of middleware layer which would decrease the load on backend. These added layers serves the purpose of security as well as logging of the events. One of the benefits of using Kong is also to ease the management of logging and incident response.
For accessing millions of rows, we will need to partition our table Responses. Partition_id will be equal to an integer marker in response table (partition id will be unique for single form). We will partition by range ( for eg. response for 10 quiz in one partition). https://developers.google.com/sheets/api/limits#:~:text=While Sheets API has no,they're refilled every minute. The docs indicate that the result should not exceed 300 requests per minute per project. Hence, we will run a cron job with inserting 300 data every minute into the google sheets.
Cron do (every minute) :
SELECT * FROM RESPONSES_100 ORDER BY created_at LIMIT 300 OFFSET 0 Offset +=300
This result will then be added to google sheet via our service.
P.S. The google sheets will not be able to handle more than 10 million cells. If the customer is looking for storing more than 10 million cells, it is preferable to use an actual database instead.
2) As the data is being entered into the collect form, the data should reflect in google sheet live.
For this use case, we first connect our application to our google account and give permission to edit add and delete google sheets.

The current integration with google sheet looks something like this:
curl 'https://collect.atlan.com/api/v1/functions/createIntegration' \
-H 'authority: collect.atlan.com' \
-H 'accept: */*' \
-H 'accept-language: en-GB,en;q=0.9' \
-H 'content-type: application/json' \
-H 'cookie: G_ENABLED_IDPS=google; G_AUTHUSER_H=1' \
-H 'origin: https://collect.atlan.com' \
-H 'referer: https://collect.atlan.com/form/sAVXzq84sGEJtKIUmov7/settings' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: same-origin' \
-H 'sec-gpc: 1' \
-H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36' \
-H 'x-parse-application-id: collect-app' \
-H 'x-parse-session-token: r:e96500d7deb1c930a6c1e4a52b846a34' \
-H 'x-requested-with: XMLHttpRequest' \
--data-raw '{"authorizationCode":"4/0ARtbsJoQsm-P4dUkKBjnsDBDTBYZcCewKG2i_Nlg552XOHM7zuxqw6Y5rH2vCt2lPVYtfA","formId":"sAVXzq84sGEJtKIUmov7",
"spreadsheetTitle":"My First Form","exportConfig":{"useOptionCode":true,"useQuestionAlias":true,"includeAllBaselineData":false,"timeZone":"Asia/Calcutta",
"excludeDeletedQuestions":true,"from":"2022-10-03T11:10:58.407Z","dateFormat":"%Y-%m-%d %H:%M","showOptionLabelAndCodeForChoiceGroup":false},
"integrationTypeCode":"GOOGLESHEETSV4"}' \
--compressedThe functions seems to be a part of the main api backend itself. But the existing system cannot add data live into the sheet as and when the data is entered into our collect form. Also, the solution is not plug-and-play.
Proposed architecture
Plug-and-play
The proposed plug-and-play microservice architecture depends on API gateway kong.
Any new service can be added as kong services with available port. If the service is not required we can simply remove it from our kong configuration. Hence, this architecture gives us flexibility to add or remove new integrations as and when required. Kong also gives flexibility to load balance by scaling services horizontally making it highly scalable. Kong also takes care of logging and we can provide these logs to specified url (our log management services) for monitoring of out application and setup system health checks and alerts. The access layer will be made of kong + casbin. Casbin provides a very efficient way to maintain RBAC (Role based acess control). When the request is made to the backend, the middlewares check the access of the users for particular services. We can remove that using an Access layer at proxy stage. Figure 5 shows the sample diagram which demonstrates how the JWT token can be unmarshaled and used in different services according to the usecases.
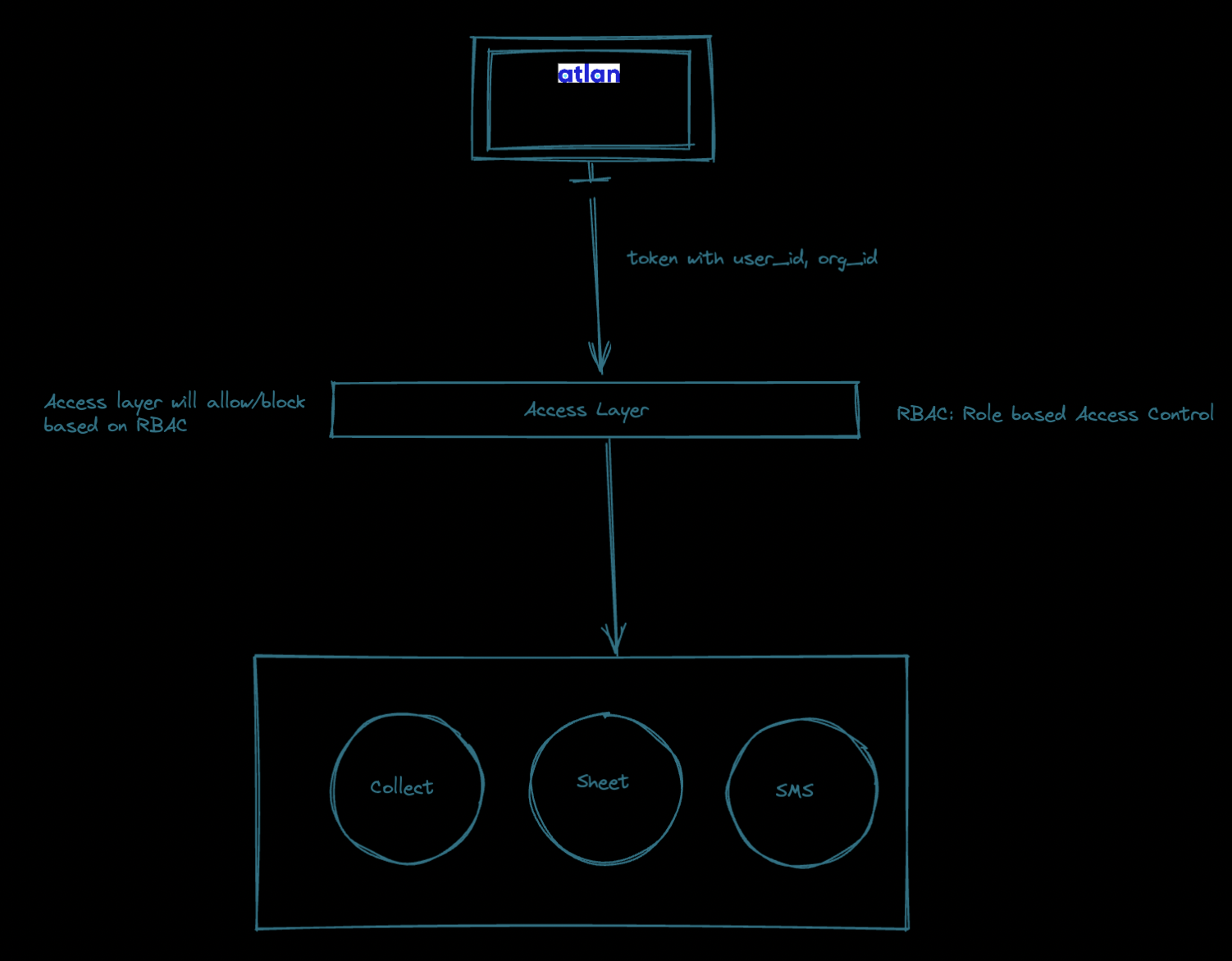
Why Casbin 🤔
The access layer becomes important because many of these integrations might be limited to certain organisation only. Let’s say the slang integration is only required by X organisation. To make sure that only certain organisation and certain users can access the feature, casbin plays an important role in maintaining the RBAC or the ACLs.
Backend Codebase 👾
Here comes the fun part, I have made a basic schematic working model of atlan collect. The models are very basic, these apis are just for reference for our plug-and-play architecture. I have made the main api in GoLang and the database of choice is PostgreSQL. Why Golang 🤔
- It is fast
- Scalable
- Can be converted to Binary
- All the cool kids use it.
- Clean code.
- I have used clean architecture for the backend. ( It took me alot of time to setup clean architecture but it was worth it :p )
Why PostgreSQL 🤔
- The usecase requires a lot of relations to be maintained among the responses, users and forms hence, it is wise to use SQL database.
- PostgreSQL in particular provides a lot of easy features for scaling like partitioning.

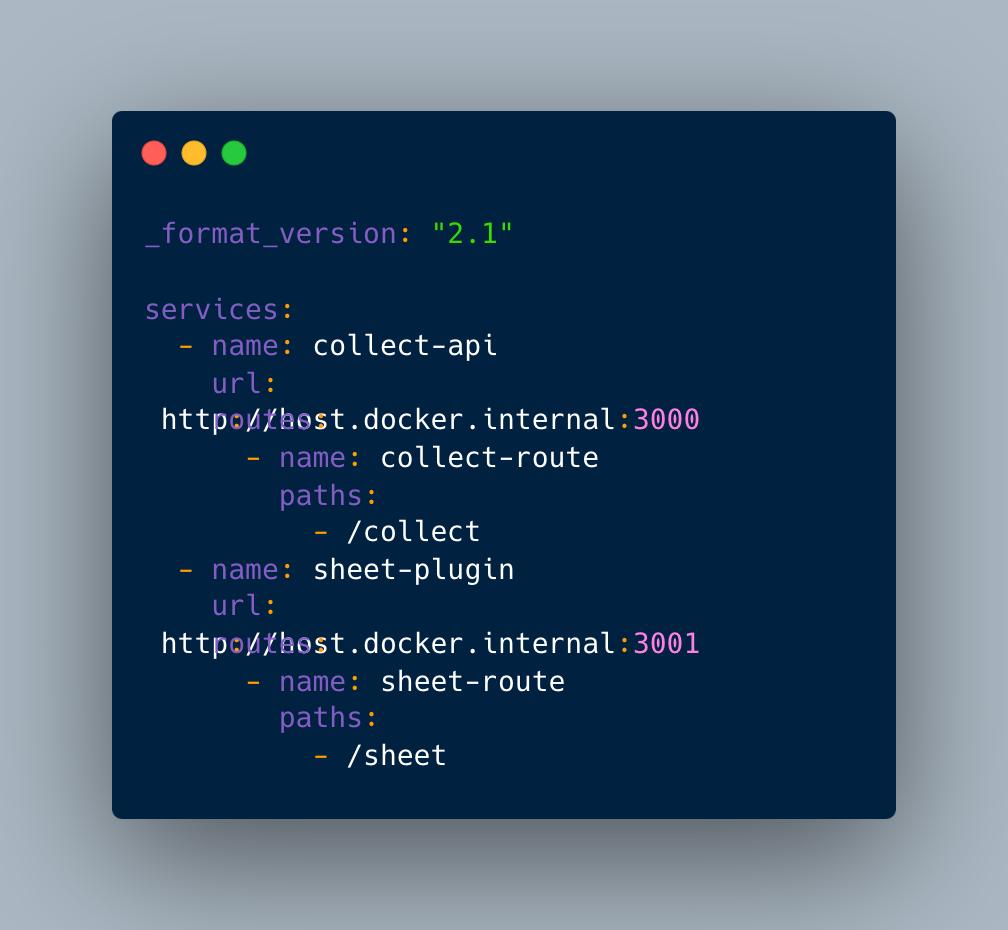
Now let’s look at our kong.yaml file for api service:
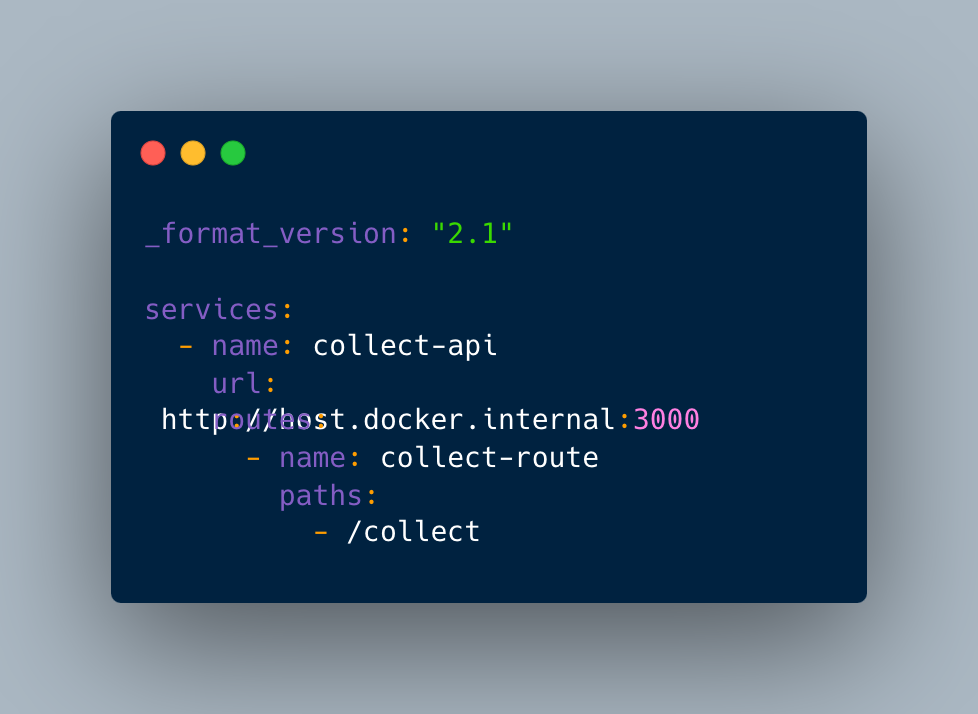
The kong is now setup and ready to serve our backend API.
Logs, monitor for system health, and alerts
I have added sentry to monitor logs and report incidents. Sentry provides us with easy integration tools like slack and hence the incident reporting and responding becomes faster and easier.
Plug-And-Play
Let’s say the client demands to add a new feature to collect the live data into google sheets.

What do we do? We make a new service and add it to our API gateway.
The Sheet Service
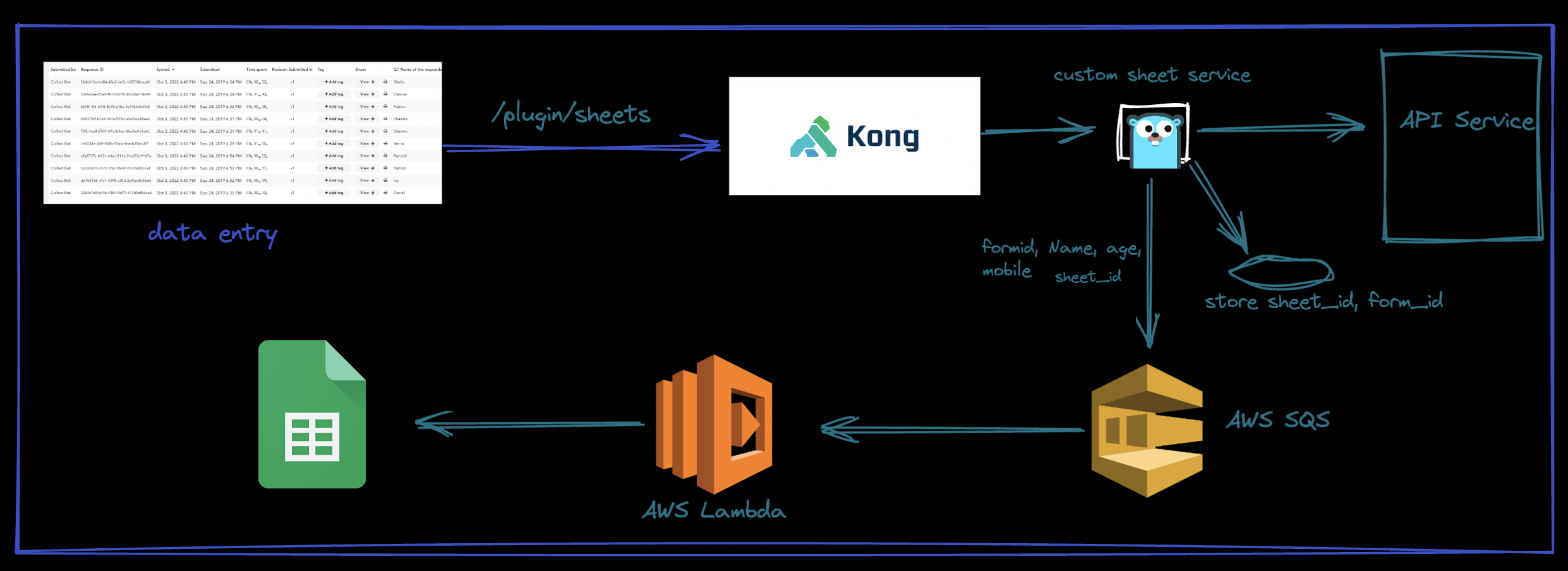
When the data is being added to collect, we send the data to plugin sheet service via kong.
The sheet service is built with node.js and mongoDB. Why Node.js
Following the KISS (keep it simple, stupid) principle and the first commandment of atlan engineering, node.js provides with a simple and fast solution. With availability of numerous packages and community, it makes the development process easier and faster.
Sheet service will check for corresponding sheet id with the form id provided from the frontend. Then it will look for google permission from the user id provided as shown in figure 3.
After getting the necessary parameters, we push the data into AWS SQS.
Why Queue?
We need to scale our application to millions of rows. While accessing the database, we need to make sure that there are no SQL locks and the data is safely added to our system concurrently. Processing a million row database takes a very long time and we need to offload these tasks to a messaging queue that can complete it’s task in the background asynchronously.
Why SQS?
We could’ve used a custom queue service with Kafka or any other messaging queue, but offloading it to AWS SQS provides better reliability, availability and discoveribility (logging and monitoring). AWS SQS is highly scalable and fault tolerant and hence meets the design needs, which makes it the best option to use.
The SQS then sends the data to AWS lambda which is a serverless function that adds the data to given google sheet. Why AWS Lambda?
The main functionality of AWS lambda would be to maintain the limit of insertion per project in google sheet i.e, the limit of writing into google sheet 300 writes/minute per project. AWS lambda will also provide a very cheap solution, as our custom sheet service will be a relatively small service, the heavy lifting of the tasks will be done by lambda and sqs. These solutions are very cheap and being serverless, we need to pay only for the writes and size of the code that we use.
The con of using lambda is that the payload is only 6mb and hence, row data > 6mb will not be able to be processed by lambda. For the sake of simplicity i have assumed that the payload will be less than 6mb. For payload >6mb my architecture would differ drastically.

Our kong file looks like this now :
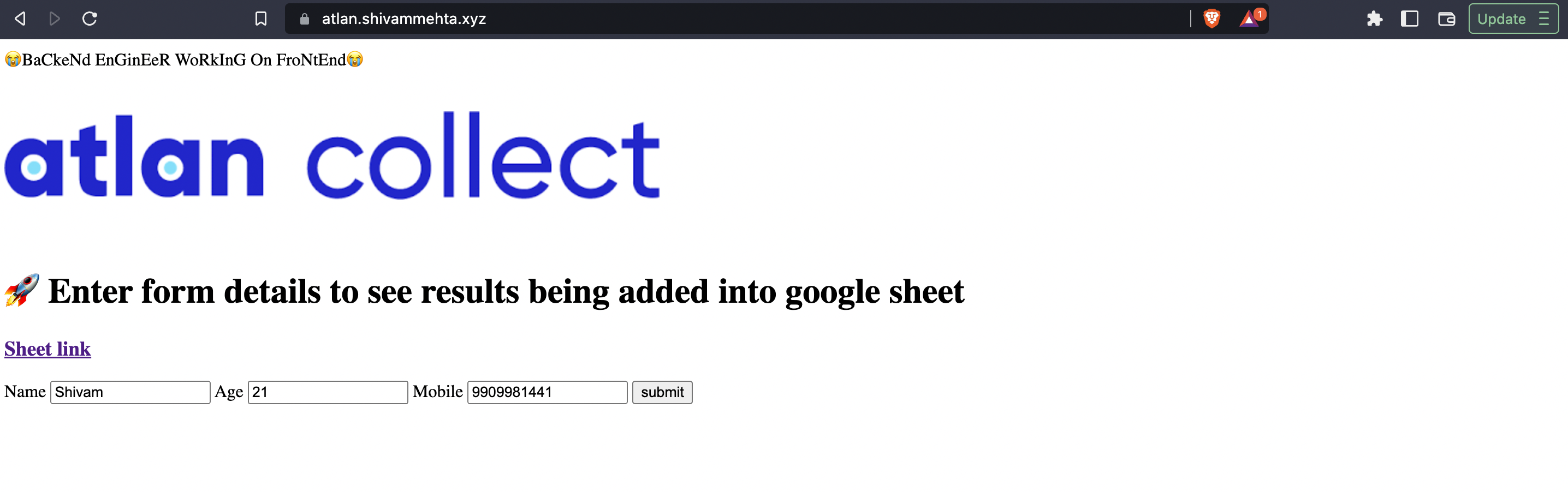
Wanna try it yourself 🤪?
atlan.shivammehta.xyz
I have hosted a basic form application that mimics the sheet service. The data takes up three data points and stores the data at google sheet : Sheet link
⚠️ The application is hosted in heroku which makes request to AWS SQS which in turn makes request to AWS lambda which inserts the data into google sheet. Code can be found in sheet serivce. You may face cold start from heroku.
The return of the client 💀
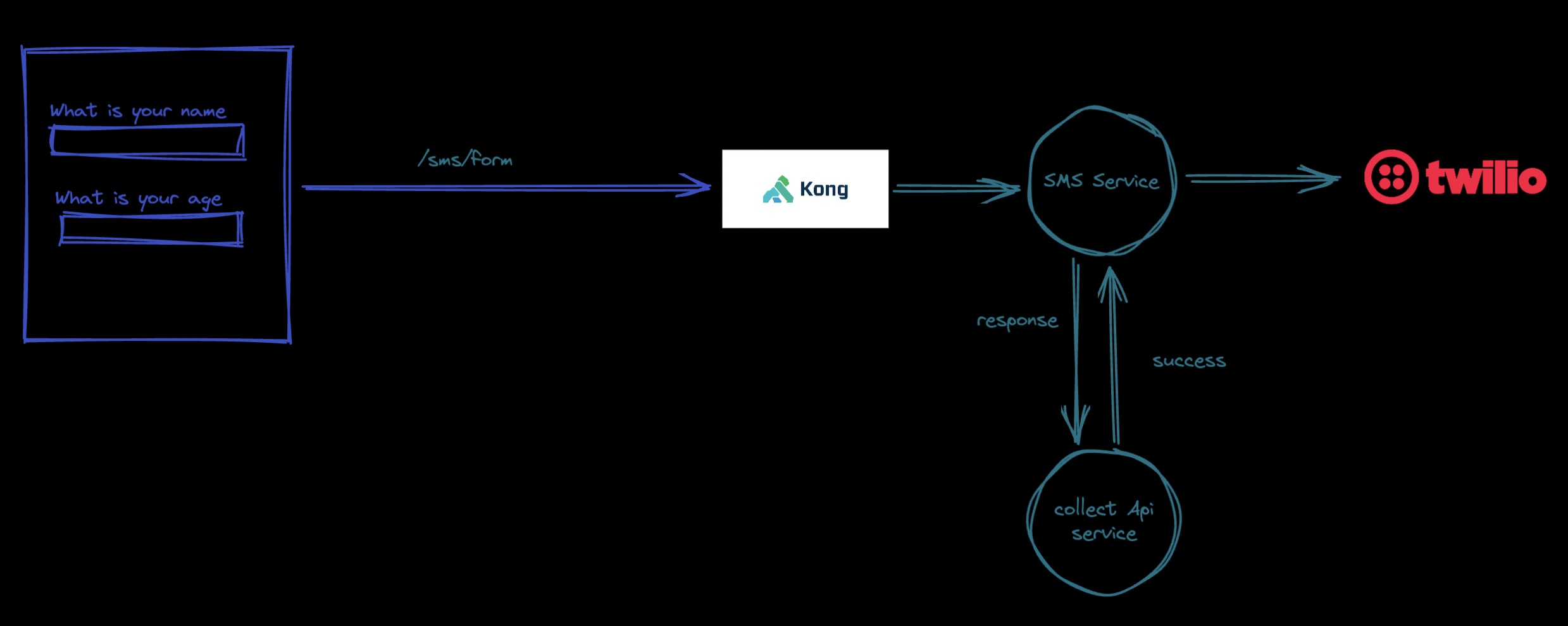
Now let’s say the client demands to send sms after a response is being received. We follow the same procedure, create a service, add it to kong, route the response submission to sms service. The sms service then validates the response send the submission to api backend service and if the response is stored, we send sms to the user.
Final kong yaml

Conclusion and future enhancements
Hey Atlan team! It was an amazing problem statement to work on. I tried to cover all the necessary intricacies. With time frame in mind and time required to develop the solution, i tried to come up with the best solution possible. Is it the best solution? Definitely not. Here are the things the architecture improve upon.
1) GRPC, the plug-and-play architecture depends on the plugin microservices making request to our main api service. Protocol buffers with their well defined binary structure can decrease the processing complexity and hence speed up the latency of moving data from one service to other.
2) The codebase is schematic, there are lot of improvements possible in writing better code for our plugins. The main api service is well architected, but the database queries needs to be improved. There is no caching layer in the backend, we can add a layer of redis cache in our form output.
In conclusion, this solution was more focused on getting the plug-and-play architecture in line without disturbing the main backend api service. There are a lot of things to discuss and think about the architecture, hopefully we can discuss it further.
Made with ❤️ by Shivam